Oracle - Database Structure
Contents
Total four parts,
Tablespaces, Datafiles,Database Blocks, Extents, Segments,Database Schema ObjectsandDatabase Logs
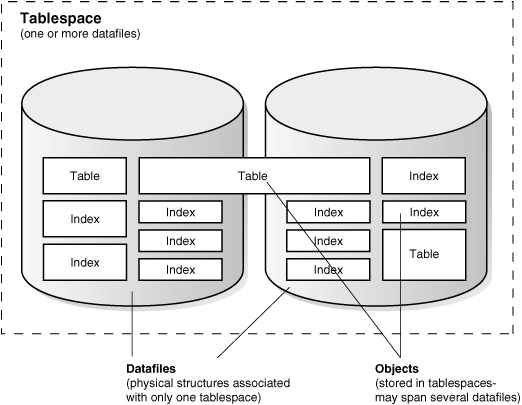
Tablespace & Datafile
Oracle Database stores logically in
tablespacesand physically indatadfilesassociated with the corresponding tablespace.
Select database free space
1 | select tablespace_name,file_id,block_id,bytes,blocks from dba_free_space; |
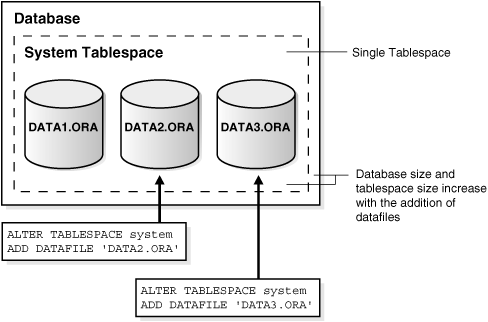
How to Allocate More Space for a Database
Enlarge a database in three ways:
Add a datafile to a tablespace
1 | -- add new datafile |
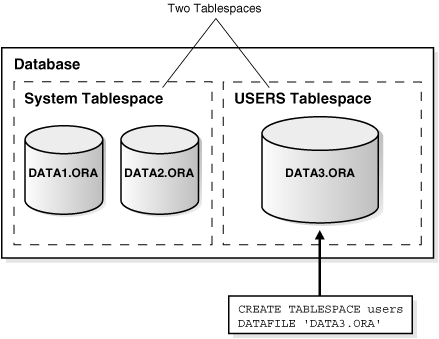
Add a new tablespace
1 | -- create new tablespace and using disk space auto mamagement |
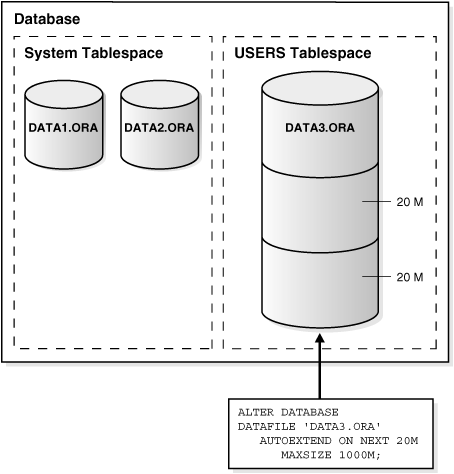
Increase the size of a datafile
1 | -- allow already exisit datafile autoextend |
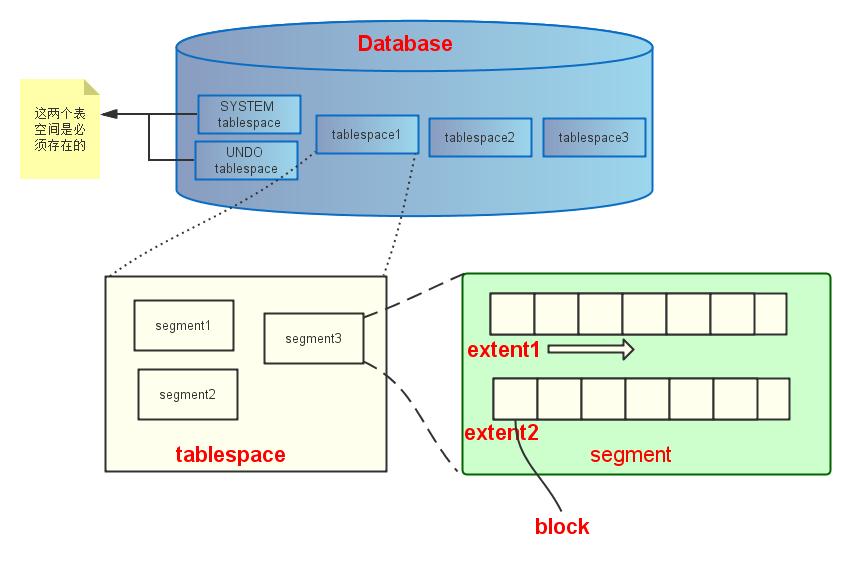
Database Blocks, Extents, Segments
From logical side to divide,
Blocks < Extents < Segments < Tablespaces
Data Block
Oracle Database manages the storage space in the datafiles of a database in units called
data blocks. A data block is the smallest unit of data used by a database. In contrast, at the physical, operating system level, all data is stored in bytes. Each operating system has ablock size. Oracle Database requests data in multiples of Oracle Database data blocks, not operating system blocks.
The standard block size is specified by the
DB_BLOCK_SIZEinitialization parameter, default value is8192 bytes.
Extents
An
extentis a logical unit of database storage space allocation made up of a number of contiguous data blocks. One or more extents in turn make up asegment. When the existing space in a segment is completely used, Oracle Database allocatesa new extentfor thesegment.
1 | Related system tables: `DBA_EXTENTS`, `USER_EXTENTS`. |
Segments
A
segmentis a set of extents that contains all the data for a specific logical storage structure within a tablespace. For example, for each table, Oracle Database allocates one or more extents to form that table’s data segment, and for each index, Oracle Database allocates one or more extents to form its index segment.
Inculde the specific data objects:Table,Index,Cluster Table, anduser segments,undo segmentsand all the typessegements.
1 | Related system tables: `DBA_SEGMENTS`, `USER_SEGMENTS`. |
Tablespaces
A database is divided into one or more logical storage units called
tablespaces. Tablespaces are divided into logical units of storage calledsegments, which are further divided intoextents. Extents are a collection of contiguousblocks.
When create default tablespace, contains
SYSTEM TABLESPACE,SYSAUX TABLESPACE,UNDO TABLESPACE,USERS TABLESPACEandTEMP TABLESPACE.
1 | Related views: `V$TABLESPACE`, `V$DATAFILE`, `V$TEMPFILE`. |
Database Schema Objects
A
schemais a collection of logical structures of data, or schema objects. Aschemais owned by a database user and has the same name as that user. Each user owns a single schema. Schema objects can be created and manipulated with SQL and include the following types of objects:
Tables,Views,Materialized Views,Indexes,Sequence,Synonyms,Clusters,Constraints,Tiggers,Database links
Tables
Tables is very basic and simple. You know how to operate table
CURD, and tables row, column, etc. Certainly, Tables has a lot of others properties, and dividePartitioned Tables,Nested Tables,Temporary Tables. etc.
1 | -- create table |
Views
It’s a virtual table that doesn’t physically exist, rather it’s created by a query joining one or more other tables.
1 | -- create view |
Materialized Views
Materialized viewsare schema objects that can be used to summarize, compute, replicate, and distribute data. They are suitable in various computing environments such as data warehousing, decision support, and distributed or mobile computing:
1 | -- Creating Materialized Aggregate Views |
And the detail usage will talk about in the later article~
Materialized Views Overview click here
Materialized Views Examples click here
Indexes
Indexesare optional structures associated withtablesandclusters. You can create manyindexesfor atableas long as the combination ofcolumnsdiffers for eachindex. You can create more than oneindexusing the samecolumnsif you specify distinctly different combinations of thecolumns.
Oracle Database provides several indexing schemes,
B-tree,Hash cluster,Bitmap, etc., By default, Oracle createsB-treeindexes.
1 | -- syntax |
Sequence
Sequencesare database objects from which multiple users can generate unique integers. The sequence generator generates sequential numbers, which can help to generateunique primary keysautomatically, and to coordinate keys acrossmultiple rowsortables.
Special attention, Uses and Restrictions of
NEXTVALandCURRVAL
1 | # cann't be used in these places: |
1 | -- create syntax - alter same as create, replace CREATE to ALTER |
Synonyms
A
synonymis an alias for a schema object. Synonyms can provide a level of security by masking the name and owner of an object and by providing location transparency for remote objects of a distributed database. Also, they are convenient to use and reduce the complexity of SQL statements for database users.
You can create both
publicandprivatesynonyms. Apublic synonymis owned by the special user group namedPUBLICand is accessible to every user in a database. Aprivate synonymis contained in the schema of a specific user and available only to the user and to grantees for the underlying object.
1 | -- I think the sql statement is very clear to express |
Constraints
Totally contains
PRIMARY KEY CONSTRAINT,UNIQUE CONSTRAINT,FOREIGN KEY CONSTRAINT,NOT NULL CONSTRAINTandCHECK CONSTRAINT, etc.
PRIMARY KEY CONSTRAINT
A
primarykey constraint designates a column as the primary key of a table or view. A composite primary key designates a combination of columns as theprimarykey. When you define a primary key constraint inline, you need only thePRIMARY KEYkeywords. When you define a primary key constraint out of line, you must also specify one or more columns. You must define a composite primary key out of line.
A primary key constraint combines a
NOT NULLandUNIQUEconstraint in one declaration.
1 | -- syntax |
UNIQUE CONSTRAINT
A
uniqueconstraint designates a column as a unique key. A composite unique key designates a combination of columns as theuniquekey. When you define a unique constraint inline, you need only theUNIQUEkeyword. When you define a unique constraint out of line, you must also specify one or more columns. You must define a composite unique key out of line.
To satisfy a unique constraint, no two rows in the table can have the same value for the unique key. However, the unique key made up of a single column can contain nulls. To satisfy a composite unique key, no two rows in the table or view can have the same combination of values in the key columns. Any row that contains nulls in all key columns automatically satisfies the constraint. However, two rows that contain nulls for one or more key columns and the same combination of values for the other key columns violate the constraint.
1 | -- syntax it's same as primary key |
FOREIGN KEY CONSTRAINT
A
foreign keyconstraint (also called a referential integrity constraint) designates a column as the foreign key and establishes a relationship between that foreign key and a specified primary or unique key, called the referenced key. A composite foreign key designates a combination of columns as the foreign key.
You can define a foreign key constraint on a single key column either inline or out of line. You must specify a composite foreign key and a foreign key on an attribute out of line.
To satisfy a composite foreign key constraint, the composite foreign key must refer to a composite unique key or a composite primary key in the parent table or view, or the value of at least one of the columns of the foreign key must be null.
Specifc Attention ON DELETE Clause
The ON DELETE clause lets you determine how Oracle Database automatically maintains referential integrity if you remove a referenced primary or unique key value. If you omit this clause, then Oracle does not allow you to delete referenced key values in the parent table that have dependent rows in the child table.
- Specify
CASCADEif you want Oracle to remove dependent foreign key values.
- Specify
SET NULLif you want Oracle to convert dependent foreign key values toNULL. You cannot specify this clause for a virtual column, because the values in a virtual column cannot be updated directly. Rather, the values from which the virtual column are derived must be updated.
1 | -- syntax |
NOT NULL CONSTRAINT
A
NOT NULLconstraint prohibits a column from containing nulls. TheNULLkeyword by itself does not actually define an integrity constraint, but you can specify it to explicitly permit a column to contain nulls. You must defineNOT NULLandNULLusing inline specification. If you specify neitherNOT NULLnorNULL, then the default isNULL.NOT NULLconstraints are the only constraints you can specify inline onXMLType andVARRAYcolumns. To satisfy aNOT NULL` constraint, every row in the table must contain a value for the column.
- You cannot specify
NULLorNOT NULLin a view constraint.
- You cannot specify
NULLorNOT NULLfor an attribute of an object. Instead, use aCHECKconstraint with theIS [NOT] NULLcondition.
CHECK CONSTRAINT
A
checkconstraint lets you specify a condition that each row in the table must satisfy. To satisfy the constraint, each row in the table must make the condition eitherTRUEor unknown (due to a null). When Oracle evaluates a check constraint condition for a particular row, any column names in the condition refer to the column values in that row.
The syntax for inline and out-of-line specification of check constraints is the same. However, inline specification can refer only to the column (or the attributes of the column if it is an object column) currently being defined, whereas out-of-line specification can refer to multiple columns or attributes.
Restrictions on Check Constraints
- You cannot specify a
check constraintfor a view. However, you can define the view using theWITH CHECK OPTIONclause, which is equivalent to specifying a check constraint for the view.- The condition of a check constraint can refer to any column in the table, but it cannot refer to columns of other tables.
Tiggers
Database
triggersare procedures that are stored in the database and activated (“fired“) when specific conditions occur, such as adding a row to a table. You can use triggers to supplement the standard capabilities of the database to provide a highly customized database management system.
1 | /* |
Clusters
A
clusterprovides an optional method of storing table data. Aclusteris made up of a group of tables that share the same data blocks. The tables are grouped together because they share common columns and are often used together.
primary benefits:
- Disk I/O is reduced and access time improves for joins of clustered tables.
- The
cluster keyis the column, or group of columns, that the clustered tables have in common. You specify the columns of the cluster key when creating the cluster. You subsequently specify the same columns when creating every table added to the cluster. Each cluster key value is stored only once each in the cluster and the cluster index, no matter how many rows of different tables contain the value.
And the detail usage will talk about in the later article~
Clusters Overview click here
Clusters Manage click here
Database links
A
database linkis a schema object in one database that enables you to access objects on another database. The other database need not be an Oracle Database system. However, to access non-Oracle systems you must use Oracle Heterogeneous Services.
By the type, It’s contain
private,public, andglobaldatabase links.
1 | -- create |
Database logs
Redo logs
Redo logscontain a record of changes that were made to datafiles. Redo logs are stored in redo log groups, and you must have at least two redo log groups for your database. After the redo log files in a group have filled up, the log writer process (LGWR) switches the writing of redo records to a new redo log group.
And specific point:
- Record of how to reproduce a change
- Used for Rolling forward database changes
- Stored in redo log files
- Protect against data loss.
How to detect
To find sessions generating lots of redo, you can use either of the following methods. Both methods examine the amount of undo generated. When a transaction generates undo, it will automatically generate redo as well.
1 | /* |
Archive logs
Oracle Database can automatically save the inactive group of redo log files to one or more offline destinations, known collectively as the
archived redo log(also called the archive log). The process of turning redo log files into archived redo log files is called archiving.
How to detect archive mode:
1 | sqlplus / as sysdba |
How to enable / disable archive
1 | # first shutdown database |
Undo logs
Undo tablespacesare special tablespaces used solely for storing undo information.
You cannot create any othersegment types(for example,tables or indexes) inundo tablespaces. Each database contains zero or more undo tablespaces. In automatic undo management mode, each Oracle instance is assigned one (and only one) undo tablespace.
Undo data is managed within an undo tablespace using undo segments that are automatically created and maintained by Oracle.
And undo records are used to:
- Roll back transactions when a ROLLBACK statement is issued
- Recover the database
- Provide read consistency
- Analyze data as of an earlier point in time by using Oracle Flashback Query
- Recover from logical corruptions using Oracle Flashback features
but, It’s different with redo:
- Record of how to undo a change.
- Used for Rollback, read-consistency
- Stored in Undo Segments
- Protect against inconsistent reads in multiuser systems
How to detect
1 | /* |
Logs and Directories
How to detect log in sql statement
1 | -- Displays all redo log groups for the database and indicates which need to be archived. |
How to list oracle directories
1 | -- list all directories in the database. |
Resources:
http://psoug.org/index.htm
https://docs.oracle.com/cd/B28359_01/server.111/b28318/physical.htm
http://database.51cto.com/art/200910/158936.htm
https://docs.oracle.com/cd/B28359_01/server.111/b28318/logical.htm
http://www.jianshu.com/p/4d388f148737
https://oraclenz.wordpress.com/2008/06/22/differences-between-undo-and-redo/
Author: itabas016
Link: https://tech.itabas.com/2016/10/14/database/oracle-kt-database-structure/
License: CC BY-NC-ND 4.0